Pred mesiacom som písal o jednej z najväčších noviniek v PowerPivote za posledných niekoľko rokov – agregácie. Ktorá je zatiaľ dostupná len v preview režime v Power BI Desktope a cloude Power BI, ale snáď sa dostane budúci rok aj do SSAS Tabularu 2019. Teraz sa pozrieme, ako presne tieto agregácie fungujú.
Na začiatok jedno upozornenie – ide ešte stále o nedokončenú funkcionalitu. Preto sa niektoré detaily môžu ešte meniť. Budem sa snažiť priebežne aktualizovať tento článok, ale nečakajte, že to podľa neho bude fungovať na 100%. Aj keď princípy fungovania by sa už meniť nemali. Agregácie sú veľká technologická novinka, ktorú budú ladiť ešte minimálne zopár mesiacov. Takže to dovtedy berte len ako informačný článok. Kde sú okrem iného vynechané niektoré kroky, ktoré vo finálnej verzii už nebudú potrebné.
Aktualizácia 18.7.2019: Agregácie sú dokončené a odteraz dostupné v najnovšom Power BI Desktope. V SSAS Tabulare 2019 zatiaľ nie sú dostupné (čo je zaujímavé, keď práve najnovší nedokončený SSAS Tabular 2019 je na pozadí aktuálneho Power BI Desktopu, a agregácie sú implementované na úrovni SSAS Tabularu).
Agregácie slúžia na urýchlenie dotazov v dátovom modeli nad veľkým množstvom dát. Do PowerPivotu v Power BI, či v SSAS Tabulare, nie je problém natlačiť aj miliardy riadkov. Problémom však začne byť výkon tohto riešenia. Ktorý sa doteraz musel obchádzať agregačnými tabuľkami a cez DAX, aby report reagoval okamžite aj nad miliardami riadkov. Podobným spôsobom, ako som načrtol ešte pred vyše 2 rokmi v jednom z článkov.
Po novom vám však budú stačiť už iba agregačné tabuľky, a zopár kliknutí v nastavení agregácií. S bonusom, že detailné dáta už nemusíte tlačiť do dátového modelu, ale môžete ich nechať v SQL databáze – či už v SQL Serveri, Oracli a pod.. Takže z terabajtov môžete skočiť až na petabajty dát, s možnosťou prekliknúť sa hocikedy až na detailné riadky. A toto keď rozbeháte, tak vo svete existuje veľmi málo nástrojov, ktoré toto dokážu. Cenou a možnosťami ale budú úplne inde ako riešenia od Microsoftu. Zvyčajne cenovo vyššie, a možnosťami nižšie…
Poďme sa teda pozrieť, ako na to, a za behu si to vysvetlíme na príkladoch.
Začneme znova našim vzorovým súborom Power BI, kde máme objednávky v tabuľke Objednávky, meny v tabuľke Meny, zoznam regiónov a krajín v tabuľke Regióny, a časovú tabuľky v tabuľke Čas. Ostatné tabuľky som kvôli prehľadnosti odstránil (ale nemá to vplyv na zložitosť riešenia). Budeme mať teda takúto schému tabuliek:
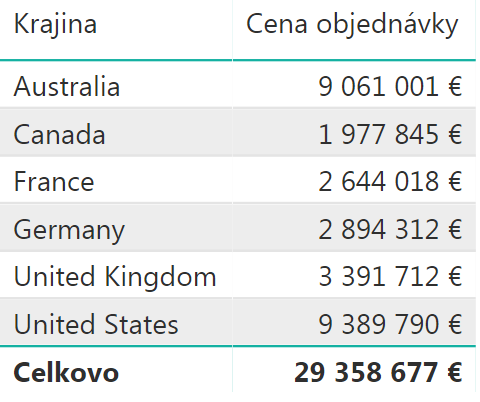
Dátový model samozrejme funguje, a keď dáme zobraziť napr. obrat po krajinách – čiže sumu stĺpca ‚Objednávky'[Cena objednávky] podľa ‚Regióny'[Krajina] – tak dostaneme klasický výsledok:
…ktorý na pozadí spustí takýto daxový dotaz:

A teraz by sme chceli tento report urýchliť. Nie že by to malo zmysel na našom vzorovom súbore, kde je len niečo cez 60 tisíc riadkov… Ale predstavte si, že ste nadnárodná firma, a tabuľka objednávok má stámilióny až miliardy riadkov. Tam už ten efekt stojí za to.
Vytvoríme teda agregačnú tabuľku, kde budeme mať predsumarizované dáta. V tomto konkrétnom prípade zoskupíme dáta z tabuľky Objednávky do novej tabuľky „Objednávky agregované“. Dáta budú zoskupené podľa stĺpcov ‚Regióny'[SalesTerritoryKey] (čiže ID regiónu) a ‚Meny'[CurrencyKey] (čiže ID meny), cez ktoré sú tieto tabuľky prepojené na tabuľku Objednávky. Ku každej kombinácii regiónu a meny bude vypočítaná suma zo stĺpca ‚Objednávky'[Cena objednávky]. Výsledok bude vyzerať takto:
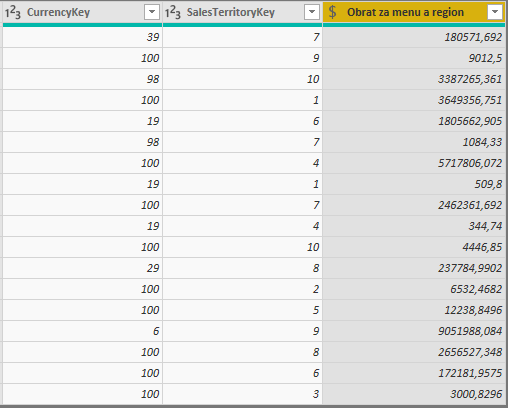
Takáto agregačná tabuľka bude použiteľná na všetky dotazy, ktoré budú chcieť sumarizovať dáta podľa ľubovoľného stĺpca z tabuľky Regióny, alebo Meny, alebo z oboch tabuliek súčasne. A samozrejme iba vtedy, keď užívateľ bude chcieť vidieť iba sumu zo stĺpca ‚Objednávky'[Cena objednávky]. Ak bude chcieť vidieť zosumované či inak zagregované ostatné stĺpce, tak sa táto agregačná tabuľka nepoužije. Resp. ak by ste chceli teraz zobraziť pre každú krajinu sumu obratu a počet riadkov, tak pre výpočet sumy sa použije agregačná tabuľka, a pre počet riadkov sa nepoužije a bude sa to počítať z detailnej tabuľky. Čo je celkom super. Veď aj my v tomto príklade máme zagregované dáta podľa regiónov, a v reporte sú dáta podľa krajín. A keďže krajiny sú jedným zo stĺpca v tabuľke Regióny, tak to pôjde z agregačnej tabuľky.
Teraz ale potrebujeme nastaviť agregácie. Prvý krok je prepojiť agregačnú tabuľku s príslušnými číselníkmi, podobne ako to mala tabuľka Objednávky:
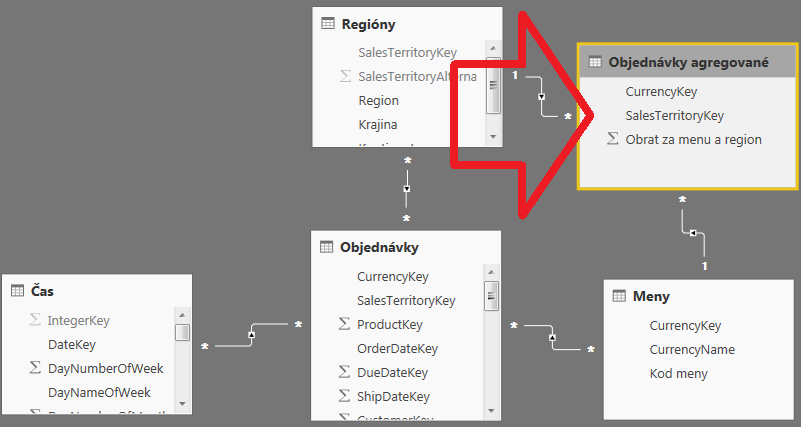
Potom v ponuke napravo kliknite na tabuľku Objednávky pravým tlačítkom myši, a vyberte položku „Spravovať agregácie“:
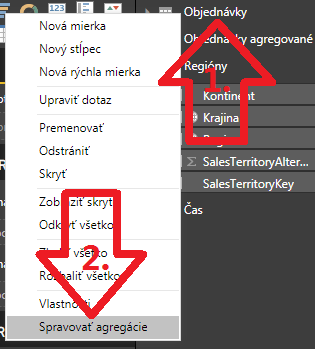
Toto okno slúži na nastavenie agregačných tabuliek pre tabuľku, z ktorej ste pôvodne vyvolali toto okno – čiže v tomto prípade pre tabuľku Objednávky:
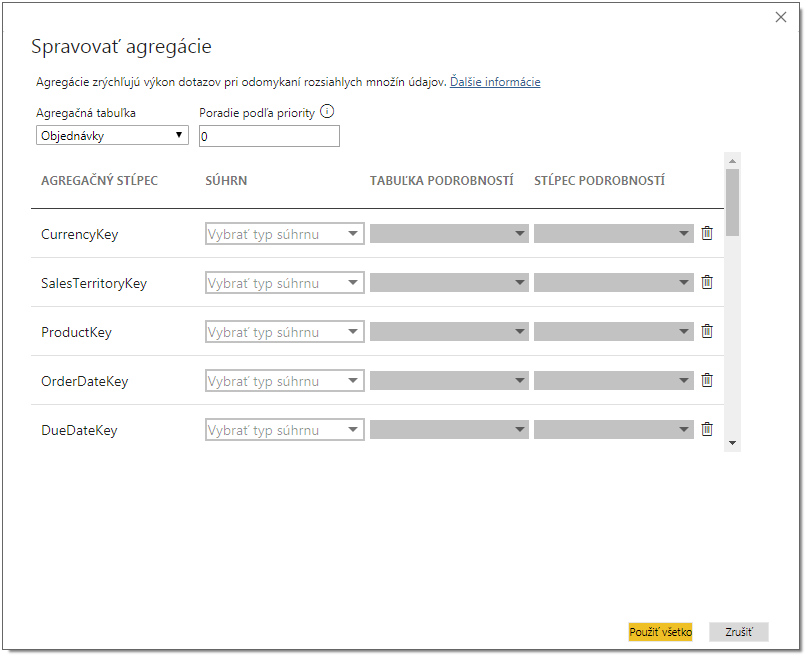
Tam vľavo hore vyberieme agregačnú tabuľku – tabuľku „Objednávky agregované“ – a v riadku pre stĺpec nazvaný „Obrat za menu a region“ povieme, že v tomto stĺpci sú zagregované dáta funkciou „Súčet“ z tabuľky „Objednávky“ pre stĺpec „Cena objednávky“:
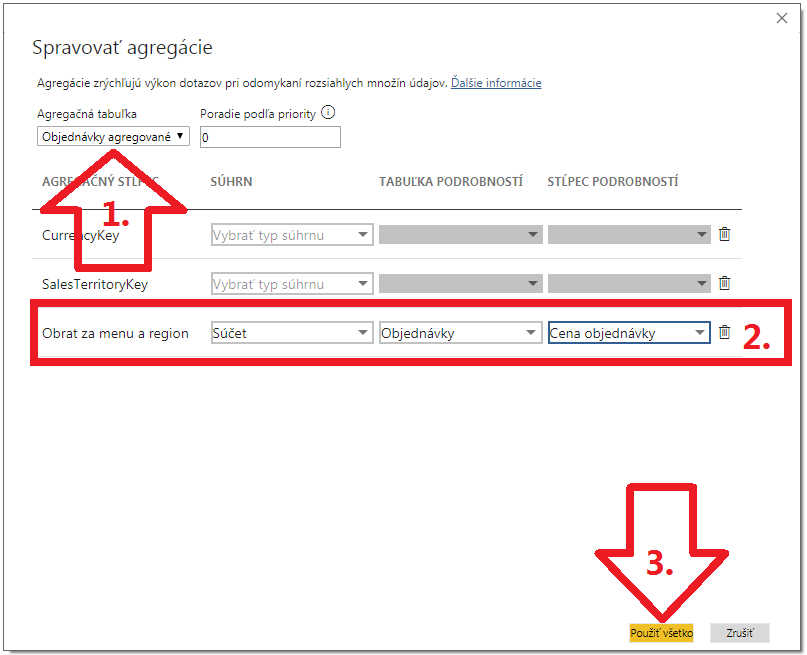
Keď to budete mať, stlačte tlačidlo „Použiť všetko“. Nie je potrebné vyberať, podľa akých stĺpcov sú zoskupené dáta v tejto agregačnej tabuľke, pretože to si PowerPivot odvodí sám podľa prepojení, ktoré sme spravili predchvíľou z tejto agregačnej tabuľky na príslušné číselníky.
Keď si dáte aktualizovať report, tak výsledok bude rovnaký. Ako však overiť, že to naozaj používa agregácie? Pri veľkých dátach by ste si mohli myslieť, veď však počkám, a ak to zbehne rýchlo, tak to zafungovalo, a ak nie, tak nie. Lenže ak aspoň trochu poznáte cache-ovací systém PowerPivotu a Power BI, tak viete, že medzi dátovým modelom a reportom sú 1-3 vrstvy cache. A výsledok mohol kľudne pochádzať aj z cache… Takže budeme radšej požadovať tvrdé dáta ako dôkaz.
Na pomoc si zoberieme najnovšie preview DAX Studia vo verzii 2.8. Momentálna verzia je 2.7.4, a tá ešte nevie zobrazovať info o agregáciách. Preto si zožeňte verziu 2.8, ak už medzičasom vyšla, alebo si ju skompilujte z rozrobených vývojárskych zdrojákov ako ja (chá chá, zasmiali sa zbrojnoši, a odcválali na šijacom stroji).
Keď teda spustíme hore uvedený daxový dotaz v DAX Studiu 2.8 a novšom, a zapneme si zobrazovanie všetkých interných vecí, tak v detailoch operácií uvidíme udalosť RewriteAttempted. A keď si na ňu klikneme, tak napravo nám zobrazí, že v pôvodnom dotaze bola nájdená a použitá zhoda z nejakej agregačnej tabuľky, a bol prepísaný pôvodný dotaz alebo jeho časť:
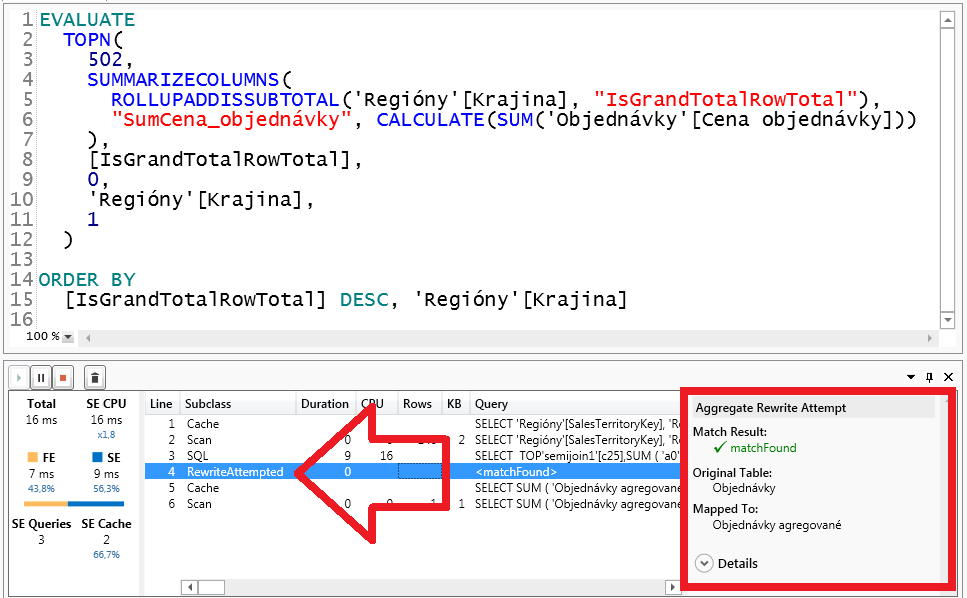
A keď si rozkliknete detaily v tých detailoch napravo, tak uvidíte presne aj ktorú:
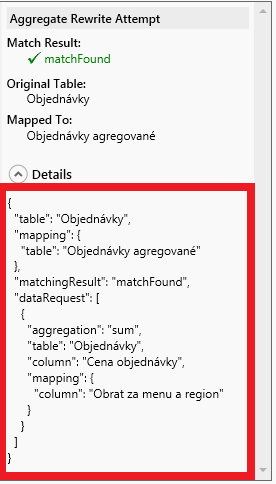
Tam vidíte, že táto konkrétna operácia zobrala zagregované sumy objednávok z našej agregačnej tabuľky. A celé to prešlo automaticky, dokonca ani Power BI nemuselo meniť dotaz. Dokonca aj keby ste namiesto toho sumovaného stĺpca použili merítko Obrat, ktoré má vzorec SUM(‚Objednávky'[Cena objednávky]), alebo sa v tom vzorci taká suma v nejakom kroku vyskytuje. Je to kvôli tomu, že agregácie sú funkcionalitou najnovšieho PowerPivotu, resp. SSAS Tabularu. Takže aj iní klienti to budú vedieť používať transparentne, bezo zmeny z ich pohľadu či z pohľadu užívateľa. A to je super, nie?
Na čo sú však potom nastavenia v okne pre agregácie, podľa akých stĺpcov sú zagregované dáta? To sa používa v prípade, že táto agregačná tabuľka nie je prepojená na zvyšok dátového modelu, alebo sú prepojenia spravené nad inými ako zoskupovacími stĺpcami. Môžete to použiť aj na tento náš, klasicky prepojený model, ale nie je to potrebné. Ako som už spomenul, tak ak sú agregačné tabuľky už prepojené na príslušné číselníky, a daná agregačná tabuľka je spravená na úrovni prepájacích stĺpcov, tak to nie je potrebné vypĺňať. Vypĺňa sa to napr. len vtedy, keby ste napr. mali časovú tabuľku, ktorá je na úrovni dní, napojenú na tabuľku objednávok, ale tie objednávky by ste mali v agregačnej tabuľke zoskupené podľa roka. V tomto prípade by ste tie tabuľky neprepájali, ale len vybrali, že daný stĺpec s rokom v agregačnej tabuľke je zoskupovacím stĺpcom pre rok v časovej tabuľke.
Potom si ešte všimnite v tom okne, kde sa nastavujú agregácie, to políčko vľavo hore, nazvané „Poradie podľa priority“:
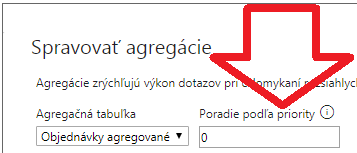
Je to tam preto, lebo pre danú detailnú tabuľku môžete zadefinovať viacero agregačných tabuliek, napr. ak máte dáta zagregované na viacerých úrovniach. Do toho políčka sa vypĺňa číslo, pri ktorom platí „čím vyššie číslo, tým viac adidas“. Čiže ak optimizér PowerPivotu nájde viacero použiteľných zhôd, tak prioritne použije tú agregačnú tabuľku, pre ktorú bude uvedené v tomto políčku vyššie číslo. To je použiteľné pre veľmi veľké dáta, kde môžete predagregovať dáta napr. na úrovni dní, a v ďalšej tabuľke na úrovni rokov. Alebo ak chcete urýchliť viacero konkrétnych kombinácií stĺpcov. Čísla priorít pre jednotlivé agregačné tabuľky nemusia sekvenčne za sebou nasledovať – pre jednu môžete použiť napr. prioritu 0, a pre druhý povedzme 5. A pôjde to aj tak.
V agregáciách sú potom schované aj ďalšie vychytávky:
- ak máte v agregačnej tabuľke stĺpce, kde jeden obsahuje súčet stĺpca, a druhý obsahuje počet riadkov, tak ich optimizér vie automaticky použiť na výpočet priemeru (funkcie AVERAGE a AVERAGEX v DAX-e),
- ak voláte funkciu DISTINCTCOUNT nad stĺpcom s unikátnymi hodnotami, a tento stĺpec je stĺpcom, podľa ktorého bola zoskupená agregačná tabuľka, tak sa sa výsledky zoberú odtiaľto – lebo v tom stĺpci sú už de facto unikátne hodnoty, a ak aj nie, tak je na nich výpočet DISTINCTCOUNT-u oveľa rýchlejší ako na detailných dátach.
Takto teda v skratke fungujú agregácie. Na ich úplné pochopenie budete potrebovať trochu viac času, alebo sa zaradiť medzi Jedi mastrov v Power BI. A najmä počkať, kým táto funkcionalita bude dokončená. Výhodou však potom bude to, že aj reporty na naozaj gigantických dátach budú zbiehať okamžite. A keď do toho zapojíte funkcionalitu „Zložené modely“ a DirectQuery, tak nemusíte mať detailné dáta v modeli, ale môžu ostať pokojne v zdrojovej databáze. Čo vám zasa ušetrí množstvo zdrojov na strane oboch serverov. A celé toto funguje automaticky, a nemusíte to obchádzať podobným štýlom, aký som načrtol v článku už pred vyše 2 rokmi. A to je naozaj bomba – nastavíte agregácie, všetko začne chodiť automatične, a nemusíte sa o nič ďalšie starať 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.