Pri pokročilejších analýzach v jazyku DAX, či už v PowerPivote, v Power BI alebo v Analysis Services, je potrebné dosť často otestovať, čo je vybrané v kontexte výpočtu. Čiže aké filtre sú použité, a ako sú použité, tak aby náš vzorec vypočítal následne správny výsledok. A na to slúžia funkcie na testovanie kontextu výpočtu, ako napr. ISFILTERED, HASONEFILTER a HASONEVALUE. Ich popis v dokumentácii však nie je každému hneď jasný. Preto si to teraz ukážeme na konkrétnom príklade.
Na začiatok však otázka – načo vôbec potrebujeme testovať kontext výpočtu, keď náš vzorec počíta to čo má počítať? Jednoducho preto, lebo v reporte zvyčajne máte niekoľko tabuliek a niekoľko polí v nich, a zvyčajne nemáte kontrolu nad tým, ktoré kombinácie stĺpcov môže a ktoré nemôže užívateľ použiť v reporte. Ani v excelovskom PowerPivote, ani v Power BI. A vo všeobecnosti musíte počítať s tým, že užívateľ môže zvoliť v reporte aj blbosť, pri ktorej nemá zmysel počítať váš ukazovateľ.
Ukážeme si to opäť na našom vzorovom súbore PowerPivotu, resp. Power BI. Spravme si na demonštráciu takúto jednoduchú kontingenčku:
- do oblasti riadkov dáme z tabuľky Čas stĺpce CalendarYear a MonthName,
- do oblasti hodnôt dáme merítko Obrat z tabuľky Objednávky.
Výsledok po rozkliknutí druhého roku bude vyzerať takto:
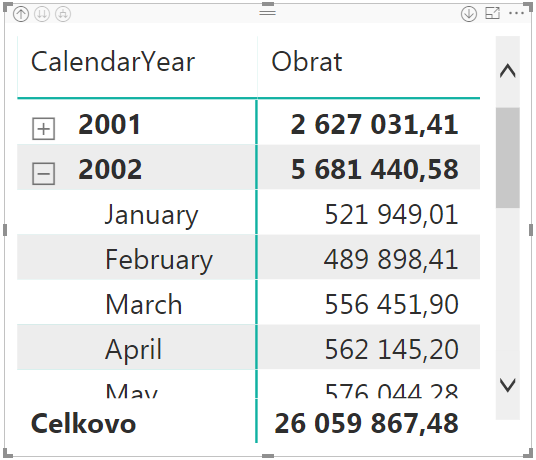
A teraz by sme chceli vypočítať Obrat pred rokom, aby sme vedeli porovnať medziročnú zmenu. Podľa staršieho článku o funkciách Time Intelligence teda označíme tabuľku Čas ako časovú tabuľku, a potom vytvoríme takéto merítko:
Obrat pred rokom := CALCULATE([Obrat]; SAMEPERIODLASTYEAR(‚Čas'[DateKey]))
Potom ho pridáme do kontingenčky, kde výsledok bude vyzerať takto:
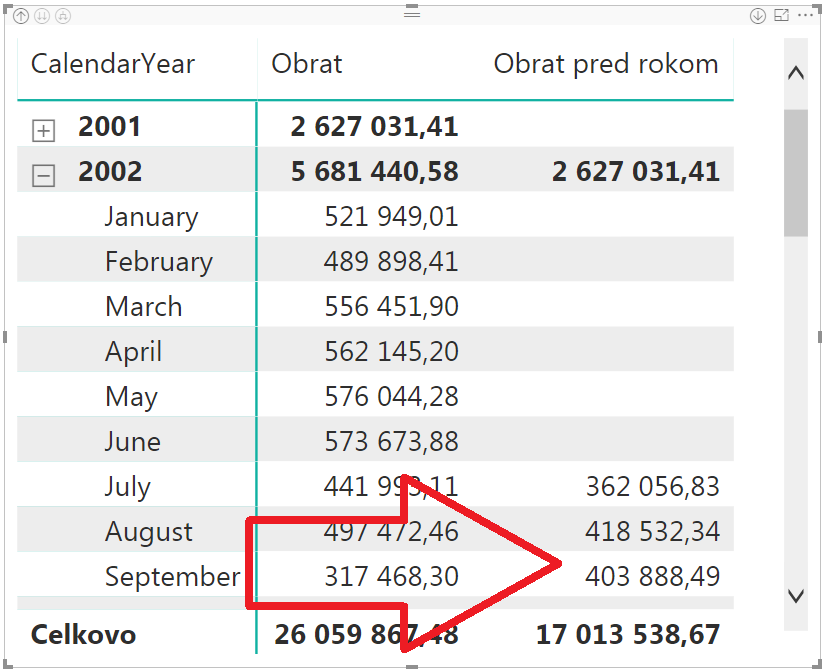
Výsledok je samozrejme správny, a na prvý pohľad je naša práca hotová. Nie však, keď naše dielo dáme užívateľom do rúk na voľnú tvorbu. Kreatívny užívateľ môže potom z tejto kontingenčky odstrániť rok, bez toho, aby mu došlo, čo robí. Alebo si jednoducho vytvorí novú kontingenčku bez roku. A zrazu sa vo výpočte nemáme o čo oprieť – v tomto prípade o konkrétny rok, voči ktorému chceme počítať obrat pred rokom. Takáto kontingenčka, napr. po odstránení roku z predošlého príkladu, bude vyzerať takto:
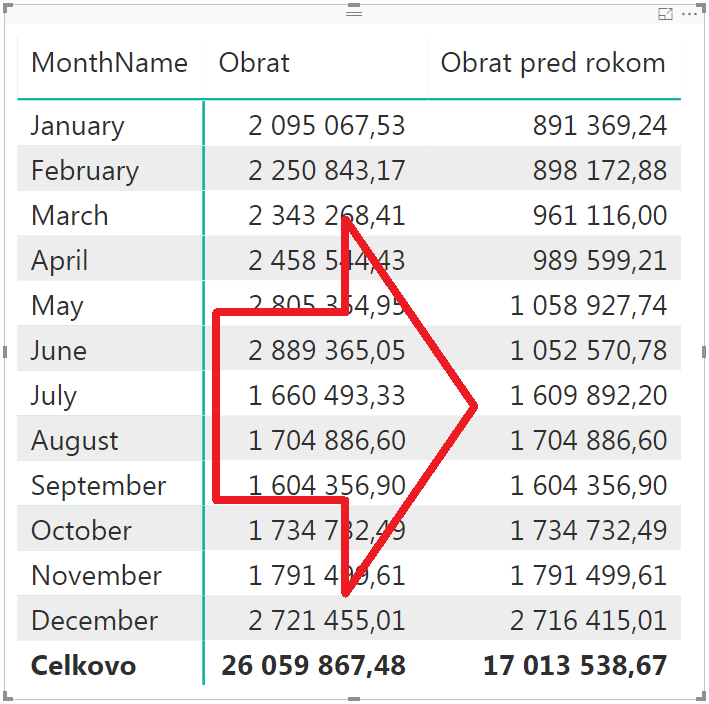
Niečo to vypočítalo, ale v oboch stĺpcoch je to blbosť. A užívateľovi to nemusí hneď dopnúť. A to je ešte len jednoduchá kontingenčka. Pri zložitom reporte, kde môže filter pochádzať z viacerých ďalších zdrojov, prípadne pri zložitejších výpočtoch, to už ani nemusí byť jasné, prečo to nejde. Preto je dobré myslieť dopredu, a pred spustením samotného výpočtu takéto prípady vopred ošetriť.
V tomto prípade je problém v tom, že sa vo výpočte „obratu pred rokom“ opierame o konkrétny rok. Lebo bez toho to nemá zmysel počítať. A keď užívateľ ten rok nezadá, tak by sme nemali vypočítať nič.
A presne na takéto prípady slúžia funkcie jazyka DAX na testovanie kontextu výpočtu, aby sme vedeli, čo je v ňom zadané, a ako presne je to zadané. A na základe toho potom buď počítali, alebo nepočítali to, čo chceme počítať. Vo väčšine prípadov sa používajú funkcie ISFILTERED, HASONEFILTER a HASONEVALUE.
Ich syntax je rovnaká:
Funkcia(stĺpec) => vracia hodnotu true/false
Každá z týchto funkcií berie na vstupe stĺpec, aby následne otestovala, či je na ňom v kontexte výpočtu zadaný nejaký filter, resp. či je kontext výpočtu filtrovaný tým stĺpcom. Na základe toho vracajú hodnotu true (pravda) alebo false (nepravda).
Na prvý pohľad by nám mala stačiť funkcia ISFILTERED, ktorá testuje, či je kontext výpočtu filtrovaný zadaným stĺpcom. V tomto prípade si spravíme takéto testovacie merítko, aby sme videli výsledok:
Test ISFILTERED rok := ISFILTERED(‚Čas'[CalendarYear])
Po jeho pridaní do kontingenčky bez roku bude vyzerať výsledok takto:
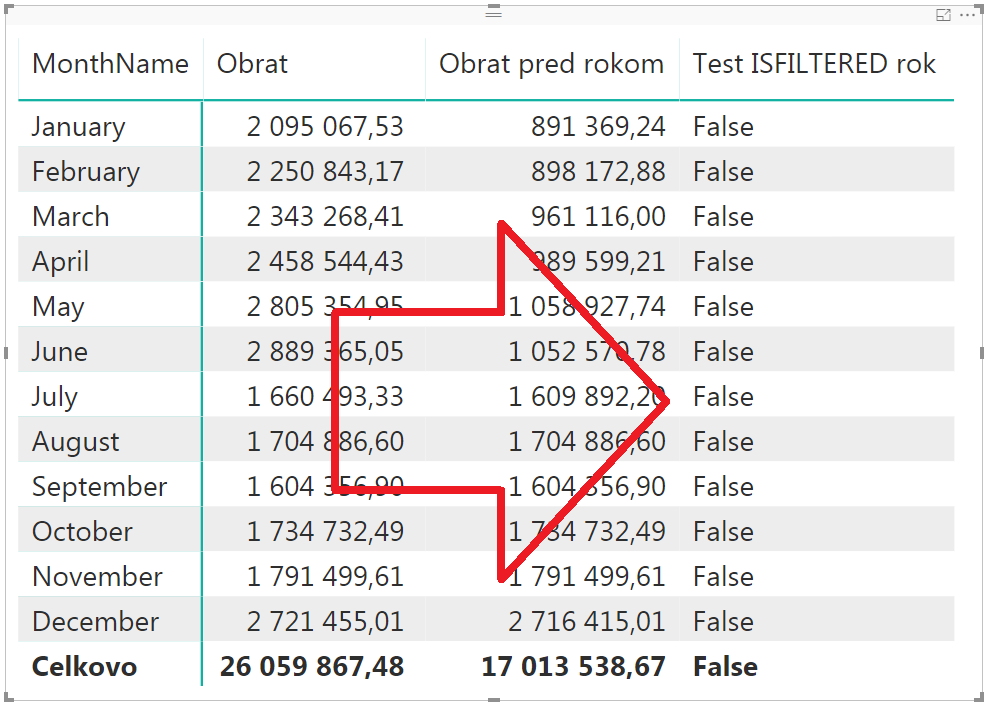
…a po pridaní roku do kontingenčky (stĺpec CalendarYear z tabuľky Čas) bude výsledok vyzerať takto:
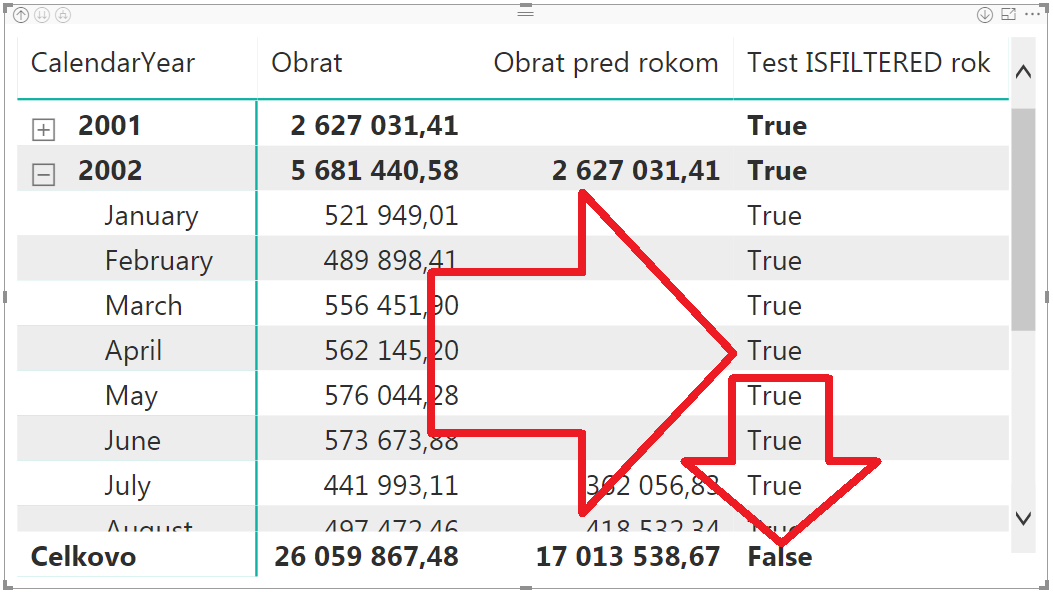
Tu vidíte, že funkcia ISFILTERED vrátila pravdu, ak bol v kontexte výpočtu použitý rok (bol zadaný filter nad rokom vďaka tomu, že rok bol v oblasti riadkov kontingenčky), a že táto funkcia vrátila nepravdu, ak v kontexte nebol použitý rok. Čo vyzerá byť na prvý pohľad správne. Opäť, až do momentu, dokým užívatelia nepreskúmajú všetky zákutia možností kontingenčiek a slicerov 😀
Aby ste videli, čo sa ešte môže stať, tak teraz z kontingenčky odstránime rok, tak aby nám tam opäť ostali iba mesiace a obraty:
Následne pridáme do reportu slicer z toho istého stĺpca, kde bol rok – zo stĺpca CalendarYear z tabuľky Čas. Potom v tomto sliceri zaklikneme prvé roky, a výsledok bude vyzerať takto:

Tam si všimnite jednu vec – v sliceri síce máme zakliknuté 2 roky súčasne, ale v kontingenčke vedľa nám funkcia ISFILTERED vracia pravdu. Lebo kontext výpočtu je tentokrát taktiež filtrovaný stĺpcom Čas[CalendarYear], keďže slicer je jeden z viacerých zdrojov kontextových filtrov. V tomto prípade je to však 2-hodnotový filter, a opäť máme problém, že pri výpočte obratu pred rokom sa potrebujeme oprieť len o jeden rok. Tentokrát však máme vybrané 2 roky, a aj keby sme počas výpočtu nejako zvolili jeden z nich, tak takýto výsledok z pohľadu užívateľa nebude jednoznačný. Alebo si ho interpretuje po svojom. A to nechcete.
Problém je v tom, že funkcia ISFILTERED testuje iba to, či je kontext výpočtu filtrovaný zadaným stĺpcom. Netestuje však už, koľkými hodnotami. Pretože na to máme iné funkcie. A táto funkcia iba jednoducho testuje, či je nastavený nejaký filter nad zadaným stĺpcom. Bez ohľadu na to, či je to 1-hodnotový, alebo viac-hodnotový filter. A my v tomto prípade potrebujeme rozlíšiť medzi týmito situáciami, pretože tento náš konkrétny výpočet obratu pred rokom má zmysel počítať iba vtedy, ak je zadaný iba 1 rok – čiže ak je zadaný 1-hodnotový filter nad stĺpcom s rokom.
Na záchranu máme dve funkcie jazyka DAX – HASONEFILTER a HASONEVALUE. Obe vrátia pravdu, ak je kontext výpočtu filtrovaný len 1 hodnotou zo zadaného stĺpca. Ak je filtrovaný viacerými hodnotami z toho stĺpca, alebo nie je filtrovaný tým stĺpcom, tak vrátia nepravdu. Overíme si to týmito dvoma testovacími merítkami:
Test HASONEFILTER rok := HASONEFILTER(‚Čas'[CalendarYear])
Test HASONEVALUE rok := HASONEVALUE(‚Čas'[CalendarYear])
Po ich pridaní do kontingenčky, a zároveň pridaní roku na riadky kontingečky, bude výsledok vyzerať takto:
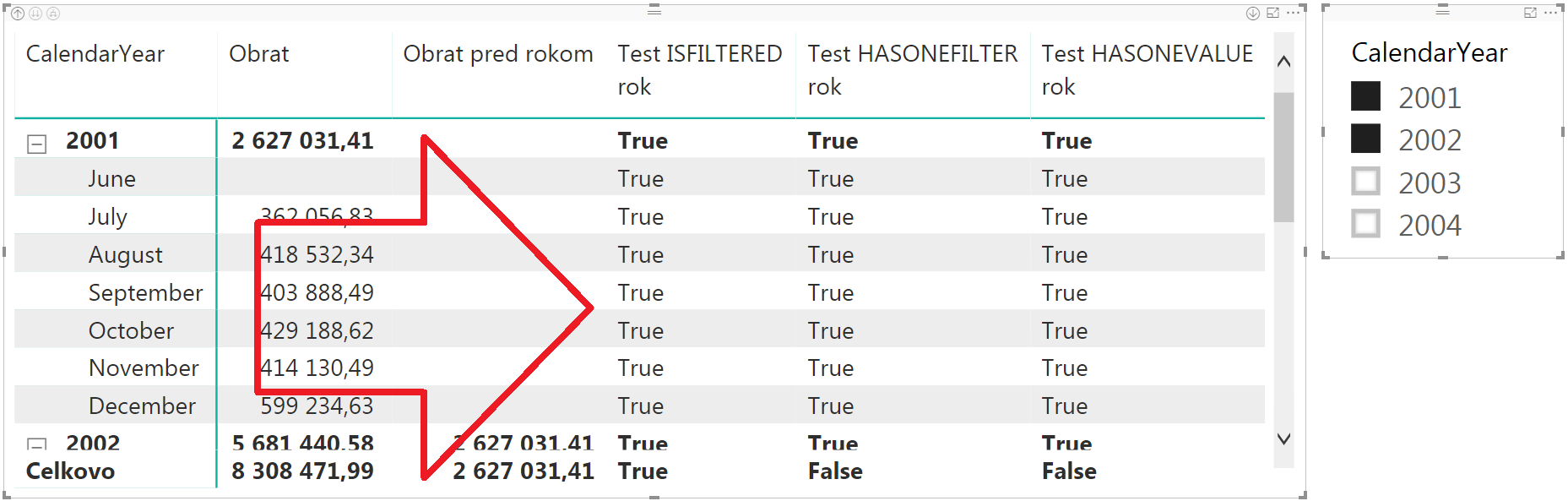
Tam vidíte, že v prípade bežných riadkov je výsledok rovnaký ako pri funkcii ISFILTERED. Pri celkovom súčte je však už výsledok odlišný. A tak je to správne. Pretože ak je súčasne zadaný nad tým istým stĺpcom 2-hodnotový filter v sliceri a 1-hodnotový filter na riadkoch kontingenčky, tak vo výsledku sa použije prienik z týchto 2 filtrov – čo je v tomto prípade 1-hodnotový filter nad rokom.
Načo však máme v jazyku DAX až 2 funkcie na testovanie toho, či je v kontexte výpočtu vybraná iba 1 hodnota z daného stĺpca? To začne byť zaujímavejšie, keď skúsime, čo sa stane, ak opäť z kontingenčky z riadkov odstránime rok:
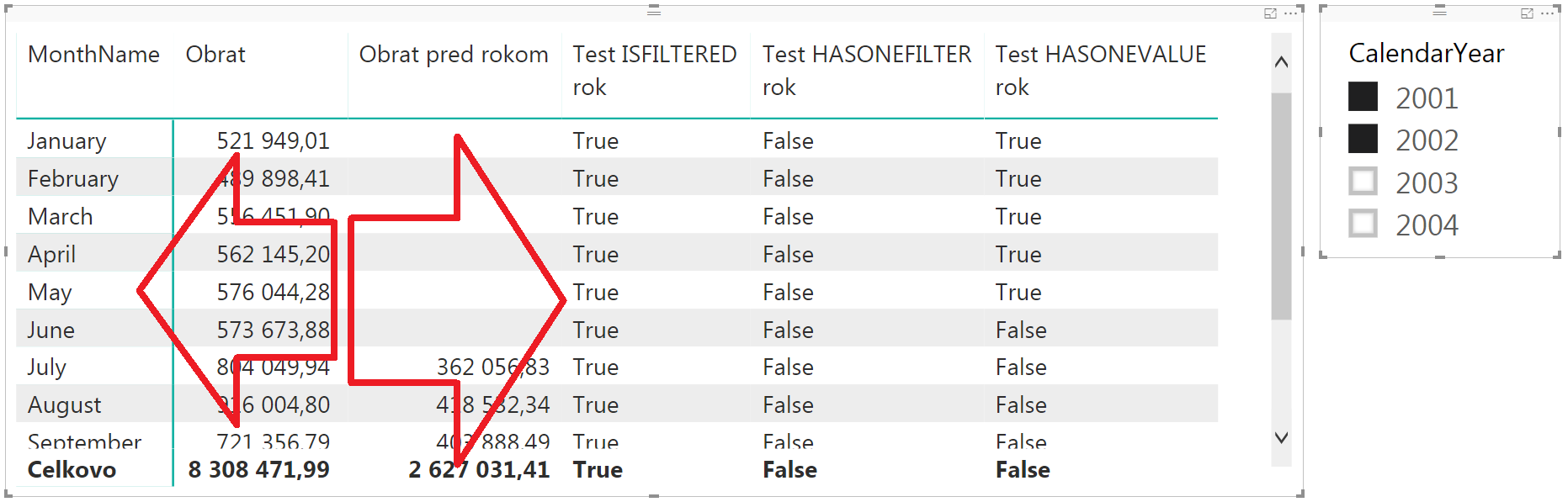
V sliceri sú ešte stále zakliknuté 2 roky, a teraz v kontingenčke vidíte rozdiel medzi tými 3 funkciami. Funkcia ISFILTERED vracia všade pravdu (pretože kontext výpočtu je filtrovaný daným stĺpcom), funkcia HASONEFILTER vracia všade nepravdu (pretože kontext výpočtu je filtrovaný 2 hodnotami z daného stĺpca s rokom, a nie 1 hodnotou), a pri funkcii HASONEVALUE by sme očakávali to isté, ako pri funkcii HASONEFILTER. Na obrázku však vidíte, že niekde vráti pravdu, a niekde nepravdu. A práve na tento detail sa zameriame.
Rozdiel medzi funkciami HASONEFILTER a HASONEVALUE je v tom, že prvá z nich vracia pravdu, ak je kontext výpočtu priamo filtrovaný 1 hodnotou zo zadaného stĺpca. A druhá z nich vracia pravdu, ak je kontext výpočtu priamo alebo nepriamo odfiltrovaný na 1 hodnotu v tom stĺpci. A teraz babo raď, čo to znamená.
Babo poradila, že sa treba pohrať s filtrami. Počet odfiltrovaných hodnôt v zadanom stĺpci závisí totižto nielen od toho, či ste zadali alebo nezadali filter nad daným stĺpcom, ale aj od toho, či ste zadali filter nad inými stĺpcami, ktorý spôsobil odfiltrovanie tohto stĺpca. Funkcia HASONEFILTER berie do úvahy iba priamo zadaný filter nad daným stĺpcom, a funkcia HASONEVALUE aj nepriamo zadaný filter, ktorý vznikol odfiltrovaním iných stĺpcov.
V našom prípade funkcia HASONEFILTER vráti pravdu, len ak je zadaný 1-hodnotový filter PRIAMO nad stĺpcom s rokom. Keďže v sliceri je zadaný 2-hodnotový filter nad daným stĺpcom, tak vráti nepravdu. Funkcia HASONEVALUE však testuje to isté, čo funkcia HASONEFILTER, plus navyše aj to, či filter nad niečím iným nespôsobil odfiltrovanie hodnôt v danom stĺpci na 1 hodnotu. Pri tomto príklade to nie je až tak zjavné, ale v našich dátach máme obraty/transakcie v prvom roku iba za mesiace júl-december, a v druhom roku za každý mesiac. Ak odfiltrujeme slicerom dáta len na tieto prvé dva roky, a začnú sa počítať bunky v kontingenčke pre každý mesiac (čiže sa nastaví dodatočný filter do kontextu výpočtu na 1 mesiac), tak vďaka tomu, že nemáme v prvých mesiacoch roka 2001 žiadne transakcie, tak napr. pre prvú bunku v kontingenčke odfiltrovanie na január 2001-2002 spôsobí v skutočnosti odfiltrovanie iba na január 2002. Pretože za január 2001 neboli žiadne transakcie. A preto je v kontexte výpočtu nepriamo použitý iba 1 rok. Práve z toho dôvodu vráti funkcia HASONEVALUE pre prvých 6 mesiacov pravdu, pretože pre prvé 2 roky existovali transakcie v týchto mesiacoch iba v 2. roku, a teda je kontext výpočtu pre tieto mesiace, vďaka mesiacom, odfiltrovaný NEPRIAMO na 1 rok. A preto aj táto funkcia vráti pravdu.
V našom konkrétnom prípade je teda pre výpočet obratu pred rokom najvhodnejšia funkcia HASONEFILTER. Pretože testuje, či je v kontexte výpočtu priamo zvolený 1 rok. Výsledný vzorec, vypeknený cez DAX Formatter, bude teda takýto:
Obrat pred rokom :=
IF (
HASONEFILTER ( 'Čas'[CalendarYear] );
CALCULATE ( [Obrat]; SAMEPERIODLASTYEAR ( 'Čas'[DateKey] ) )
)
A po dosadení do kontingenčky, kde naspäť pridáme roky, rozklikneme ju na mesiace, a odstránime testovacie merítka, bude výsledok vyzerať takto:
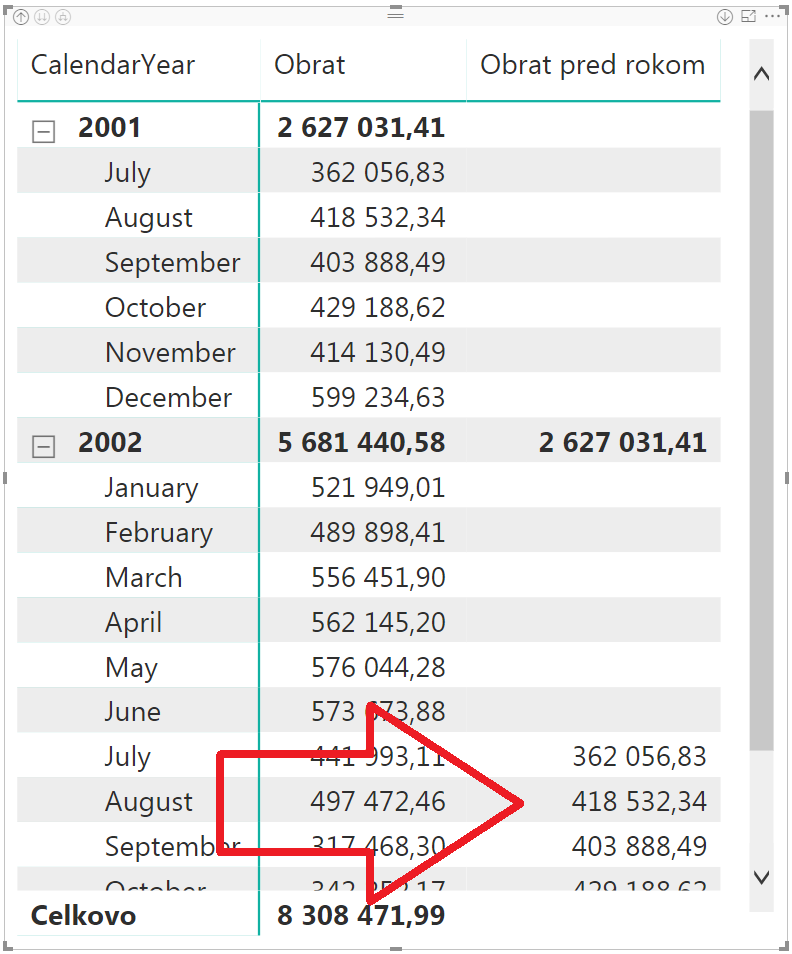
Obrat pred rokom sa bude počítať iba vtedy, keď je v kontexte výpočtu zadaný iba 1 rok. A nebude sa počítať, ak nie je zadaný iba 1 rok – ako napríklad v celkovom súčte, na ktorý ste predtým pravdepodobne nemysleli, ale teraz ho máte automaticky opravený tiež. Pretože na úrovni celkového súčtu zvyčajne nemá zmysel počítať obrat pred rokom, ak nie je v jeho kontexte vybraný iba 1 rok.
Takýto je teda rozdiel medzi týmito funkciami. Niekedy chcete testovať priamo zadané filtre, niekedy aj nepriamo zadané filtre, a niekedy len jeden z nich. Prípade iba odfiltrovanie na zadaný stĺpec bez ohľadu na počet hodnôt. Každá z funkcií ISFILTERED, HASONEFILTER a HASONEVALUE má svoje použitia, a každú z nich teda treba presne ovládať do posledného detailu, ak chcete mať spoľahlivé výsledky za každých okolností. Preto nie je žiadna z nich lepšia ani horšia. Len majú svoje konkrétne použitie v konkrétnych prípadoch. A preto ich tam toľko aj máme. Tých prípadov je viac, a aj tých funkcií je ešte viac. Dopodrobna sa im však venujem aj s viacerými konkrétnejšími príkladmi na pokročilom kurze PowerPivotu a Power BI, aby tu z toho nebol článok na 20 strán 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.
dobrý den, chtěl bych požádat o radu.
mám několik tabulek se seznamem organizací.
Jedna vzniká importem a ostatní dax příkazem.
V sestavě používám Filtry na všech stránkách kde je vybírána jedna organizace z importované tabulky.
Je nějaký způsob filtrování ostatních DAX tabulek organizací?
Zkoušel jsem selectedvalue, ale to nefunguje.
Existuje nějaký způsob jak toho docílit? relace použít nemůžu, protože každá z uvedených tabulek má relaci na jinou fact tabulku. jednu tabulku na několik fact tabulek taky nejde použít.
Dobrý deň,
Ak chcete filtrovať cez neprepojené tabuľky, tak budete musieť v každom výpočte použiť funkciu TREATAS, alebo použiť techniku virtuálneho prepojenia tabuliek z mojej knihy o Power BI a DAX.
Děkuji za odpověď.
Problém je v tom, že nepotřebuji vytvářet míry a v nich využít nepropojené tabulky.
Potřebuji vytvořit tabulku v modelu takže to dělám takto
dimOrganizaceFiltrovaná = dimOrganizace
ale toto mi vytvoří tabulku se stejným obsahem. Já bych na pravé straně potřeboval nějaký vzorec, co mi do levé tabulky vrátí dynamicky jen záznamy, které uživatel v reportu zaškrtl ve Filtru pro všechny stránky. Předpokládám, že má povoleno zaškrtnout JEN jednu hodnotu a tu jsem schopen zjistit přes SELECTEDVALUE.
K tomu je pravá tabulka ještě omezována přes RLS
Tabulka dimOrganizaceFiltrovaná je následně propojena na seznam dokladů, který se nabízí v průřezu a tam se nabízí doklady všech organizací. Potřebuji ten seznam omezit na doklady vybrané organizace.
Je ale možné, že pro tuto situaci řešení neexistuje.
Dobrý deň,
Vypočítané tabuľky nereagujú na užívateľské filtre, pretože sú vypočítané vopred v dátovom modeli. Na filtre vedia reagovať iba merítka. Ak chcete, aby filter reagoval na užívateľský výber, tak vyrobte slicer (v slovenčine „rýchly filter“, v češtine „prúřez“), a nastavte filtrovanie jeho položiek podľa užívateľovho výberu – napríklad tak, ako je to popísané v tomto článku:
https://www.powerpivot.sk/ako-zobrazit-iba-pouzite-hodnoty-v-sliceri/
Slicer vie zároveň filtrovať všetky strany reportu, ak ho nastavíte ako synchronizovaný slicer.